1. There are three types of memory:
The TM (Translation Memory), the TB (Termbase) and the lexicon for each project.
- The TM is a database where you can save the sentences from your source text together with your finished translation.
- The TB is a terminology database which you can use for single words or whole phrases.
- The lexicon is a database which only applies to the individual project. For every project file you can create a new lexicon.
When you then work on your project DVX2 combines the content of these three database types to suggest translations and help you in your work. The methods which DVX2 uses to make these suggestions are known as “Pretranslate”, “Assemble” and “AutoAssemble” – but that is another topic for another day.
2. Big Mama and Big Papa:
You can keep all of your work in just one TM (“Big Mama”) and one TB (“Big Papa”). If you are careful to give your entries the appropriate subject and client codes, DVX2 will take these codes into account when suggesting translations from your databases. My main TM contains about 40,000 sentence pairs accumulated over 12 years, and my main TB has about 55,000 entries.
3. Separate TMs and TBs:
In DVX2 Professional you can have up to 5 TMs and 5 TBs open in any project, and DVX2 Workgroup has no limitation. So you can use your Big Mama/Papa together with external databases, e.g. a TM or terminology list provided by the client, general reference material such as the EU DGT database, or terminology lists from major enterprises such as Microsoft, SAP or from various banks. Or you may even decide to keep separate databases for different subjects or clients instead of a Big Mama or Big Papa. You may feel that this is safer if you work on texts for competing engineering or IT firms which deliberately use different terminology for their own brands. The problem is that it may be more difficult to access all of your reference material, for example if you know that you have dealt with a term or sentence in DVX2, but you can’t remember which database you were using at the time.
4. Fuzzy matching:
You can allow DVX2 to find matching material which is not quite exact. Under Tools>Options>General you can set a percentage figure for the variants which DVX2 is allowed to find (= “Minimum Score”). The default setting is 75%, but depending on the type of inflections which occur in your languages it may be useful to set it to 50% or less. The percentage applies to both the TM and TB. It does not apply to the lexicon – only exact matches are found in the lexicon. And the “minimum score” does not affect the performance of the DVX2 functions DeepMiner and AutoWrite.
5. Adding new entries:
This is very quick and easy in DVX2. For the TM you enable AutoSend (either with the tick box at Tools>Options>Environment, or via the icons at the bottom of the DVX2 window – AutoSend is the second icon from the right). Then all you need to do is click CTRL-DownArrow when you have finished each segment. For the lexicon you have to highlight the word or phrase in the source and target text, then hit the F10 key. For the TB you again highlight the word or phrase in the source and target text, then hit F11. This brings up the following window:
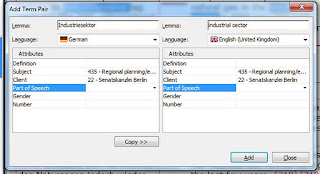 Here you can edit the term in either language to add or remove declensions, correct spelling problems etc. You can check that the terms are marked with the right subject and client codes. There are additional fields, too (Definition, Part of Speech, Gender, Number, and you may also see a field called Context). I have not yet seen any reason to use any of these fields, although some users may have found ways to do so.
Here you can edit the term in either language to add or remove declensions, correct spelling problems etc. You can check that the terms are marked with the right subject and client codes. There are additional fields, too (Definition, Part of Speech, Gender, Number, and you may also see a field called Context). I have not yet seen any reason to use any of these fields, although some users may have found ways to do so.
The termbase (TB) is one of the keys to productivity in DVX2. It is advisable to add words, and even whole phrases, as often as you can. Some users have the principle of adding an entry to the TB in every single sentence they translate. Steven Marzuola’s article about using the terminology database was based on the previous version of DVX (now often called DVX1), but it offers great advice which is also relevant to DVX2.
6. Subject and client codes:
These are important, because DVX2 refers to them when it decides what material to offer to help you with your current translation. When you first install DVX2, you will see a suggested list of subjects, but you can easily delete this and create your own list if you think this is better for your work. Each subject consists of a short index code (435 in my example above) and a descriptive text (Regional planning/ecology). When DVX2 decides how close the subject is to your current project, it works hierarchically, so in this example it would consider that entries with my subject codes 43 (Urban planning) and 4 (Building) are closely related. You can use letters instead of numbers if this suits your work.
7. Build lexicon:
This is a function which you can find in the “Lexicon” menu, and which is sometimes useful in preparation for a job which is heavy on terminology. I use this function for between 5% and 10% of my jobs. My procedure is as follows. First I call up “Build lexicon” and define the maximum number of words (usually 4). The program then takes a couple of minutes to find solutions. Then I open the lexicon (with the Project Explorer), click on the heading over the left hand column and define the sort criteria: 1. Number of words (descending), 2. Frequency (descending). Then I go through the list manually from the top. First I decide which four-word phrases are worth adding a lexicon entry for. This is usually only worthwhile for phrases which are meaningful in themselves and which occur frequently. When I get down to phrases which appear three times or less, I then use the scroll bar to move down to the most frequent three-word phrases. And so on, until I have defined a number of lexicon entries. Then I select “Remove entries” from the Lexicon menu, click on “Entries with empty targets” and OK. Typically, this gives me between 30 and 50 lexicon entries for a job consisting of several hundred segments, but they are entries which occur frequently and require consistency, so this preliminary process improves the results achieved by Pretranslate or Assemble as I work on the job.
This function (Build lexicon) can also be used to identify terms that can be used for a terminology list to be delivered to the client if this is part of the client’s instructions for the job. Over the years I have only had one such project, but this may be relevant for translators who often work in highly technical fields.
8. Names, places and proprietary titles:
These are the classic elements which should be added to the lexicon. If you have a product name or number, this is normally only relevant to the job in hand. You do not usually want this term to occur in jobs for other clients. The same applies to the names of the people who work for the client. Therefore, such elements should only be sent to the lexicon, and not to the termbase. But some names occur so often that they may be useful in the TB. My general principle here: if names could be confused with actual words in the language, they are not suitable for the TB. So the common German name Helmut is not in my TB because, depending on the level of fuzzy matching, it could be confused with the word Helm=helmet (and the declined forms Helme/Helmen/Helmes). Similarly, the surname Kohl is not in the TB to avoid confusion with Kohl=cabbage (and the near-match Kohle=coal). But the two names together are in the TB – i.e. the former German Chancellor Helmut Kohl. And other famous politicians are there too with the spelling in German and English, such as Gorbatschow/Gorbachev.
9. Adapting your use of the databases to your languages:
In some cases, your language pair and translation direction will influence the way you use the different databases because of issues such as word order and inflection. One example of this is the English phrase “public green spaces”. In French the words come in a different order, e.g. “espaces verts publics”, and alternative wordings are possible, e.g. “espaces verts des lieux publics”, “espace verts ouverts au public”, “espaces verts pour le public” etc. (Thanks to Dave Turner for providing these and other examples). In German the first translation that comes to mind is “öffentliche Grünflächen”, although the first word could also be declined as “öffentlichen”.
If you are translating from French to English, you will probably want to enter each and every French phrase as a lexical unit, especially if it occurs frequently in the type of text you deal with. Merely entering the elements does not help very much, because the order of the words must be changed. Depending on your type of work and the frequency of such phrases, you may decide to store them in the lexicon, the TB or the TM.
If you are translating from German, in this case it is sufficient to add the two words to the termbase and let DVX2 handle the endings as “fuzzy matches”. Even if we consider phrases with a greater number of inflected variants such as “public building”, (“öffentliche Gebäude”, “öffentliches Gebäude”, “öffentlichen Gebäudes”, “öffentlichem Gebäude”), it is still possible to enter just one version of each word and use fuzzy matching. The advantage here is that although the German source is inflected, the English target phrase is not.
Translating from a largely uninflected language into inflected languages like French and German can be more complicated, so you will have to find a strategy which fits the languages that you work with. There is no single solution which will work for all languages and all subject areas, but DVX2 offers flexibility in the use of the databases.
10. Looking things up in the database:
There are various ways to access the information that is in your databases. The first is that DVX2 uses this information to compile its suggested translation (when you use the functions “Pretranslate”, “Assemble” or “AutoAssemble”). When you have done that, you will see that some words or phrases in the suggested translation are underlined in blue. These are terms for which your databases contain several possibilities. Right clicking on the word or phrase will show you the other suggestions, and you can examine these and select them with the mouse or by using the number shown. The third way to see the relevant content of your database is by looking at the “Portions” window or windows. There are several screenshots illustrating this here. The fourth way to look up the information is to use Scan (CTRL-S) to call up a concordance from the TM, or Lookup (CTRL-L) to see entries from the TB.
11. Moving databases to another computer:
If you need to move your work to a different computer, e.g. to work on a laptop while you are travelling, you will need to copy certain files to the other computer. The first file is your project file, which has the extension .dvprj. The project file contains the lexicon, so no special steps are needed to transfer the lexicon. The termbase is a single file with the extension .dvtdb. The TM consists of at least four files. The main content is in a file with the extension .dvmdb. Then there is an index file for each of your languages; my index files have the extension en.dvmdi and de.dvmdi (for English and German). There is also a file with the extension .dvmdx. When you open the project on the other computer, DVX2 may complain that it cannot find the databases. But this is not a problem – when the project is open, you can select them with Project>Properties>Databases.
Another file which is worth moving to the other computer is the settings file with the extension .dvset. This contains your subject and client lists and various other settings. And don’t forget your dongle, or if you use an electronic licence key, make sure that the key will apply to the other computer.
12. How to find out more:
For more detailed information it is worth looking at the DVX2 User Guide for DVX2 Professional or DVX2 Workgroup. The link is at the bottom of the page, and the user guides are PDF files with over 600 pages. On the website http://www.atril.com there are also links to various videos, webinars and training courses, and also to the mailing list dejavu-l (under Support>Technical forum).
I already mentioned Steven Marzuola’s article on terminology databases. It is also worth looking at Nelson Laterman’s collection of tips and tricks for DVX1 (and even its predecessor DV3).
I am sure there are plenty of tips and questions which I have not covered, so I am looking forward to reading comments by my readers.
2. Big Mama and Big Papa:
You can keep all of your work in just one TM (“Big Mama”) and one TB (“Big Papa”). If you are careful to give your entries the appropriate subject and client codes, DVX2 will take these codes into account when suggesting translations from your databases. My main TM contains about 40,000 sentence pairs accumulated over 12 years, and my main TB has about 55,000 entries.
3. Separate TMs and TBs:
In DVX2 Professional you can have up to 5 TMs and 5 TBs open in any project, and DVX2 Workgroup has no limitation. So you can use your Big Mama/Papa together with external databases, e.g. a TM or terminology list provided by the client, general reference material such as the EU DGT database, or terminology lists from major enterprises such as Microsoft, SAP or from various banks. Or you may even decide to keep separate databases for different subjects or clients instead of a Big Mama or Big Papa. You may feel that this is safer if you work on texts for competing engineering or IT firms which deliberately use different terminology for their own brands. The problem is that it may be more difficult to access all of your reference material, for example if you know that you have dealt with a term or sentence in DVX2, but you can’t remember which database you were using at the time.
4. Fuzzy matching:
You can allow DVX2 to find matching material which is not quite exact. Under Tools>Options>General you can set a percentage figure for the variants which DVX2 is allowed to find (= “Minimum Score”). The default setting is 75%, but depending on the type of inflections which occur in your languages it may be useful to set it to 50% or less. The percentage applies to both the TM and TB. It does not apply to the lexicon – only exact matches are found in the lexicon. And the “minimum score” does not affect the performance of the DVX2 functions DeepMiner and AutoWrite.
5. Adding new entries:
This is very quick and easy in DVX2. For the TM you enable AutoSend (either with the tick box at Tools>Options>Environment, or via the icons at the bottom of the DVX2 window – AutoSend is the second icon from the right). Then all you need to do is click CTRL-DownArrow when you have finished each segment. For the lexicon you have to highlight the word or phrase in the source and target text, then hit the F10 key. For the TB you again highlight the word or phrase in the source and target text, then hit F11. This brings up the following window:
 Here you can edit the term in either language to add or remove declensions, correct spelling problems etc. You can check that the terms are marked with the right subject and client codes. There are additional fields, too (Definition, Part of Speech, Gender, Number, and you may also see a field called Context). I have not yet seen any reason to use any of these fields, although some users may have found ways to do so.
Here you can edit the term in either language to add or remove declensions, correct spelling problems etc. You can check that the terms are marked with the right subject and client codes. There are additional fields, too (Definition, Part of Speech, Gender, Number, and you may also see a field called Context). I have not yet seen any reason to use any of these fields, although some users may have found ways to do so.The termbase (TB) is one of the keys to productivity in DVX2. It is advisable to add words, and even whole phrases, as often as you can. Some users have the principle of adding an entry to the TB in every single sentence they translate. Steven Marzuola’s article about using the terminology database was based on the previous version of DVX (now often called DVX1), but it offers great advice which is also relevant to DVX2.
6. Subject and client codes:
These are important, because DVX2 refers to them when it decides what material to offer to help you with your current translation. When you first install DVX2, you will see a suggested list of subjects, but you can easily delete this and create your own list if you think this is better for your work. Each subject consists of a short index code (435 in my example above) and a descriptive text (Regional planning/ecology). When DVX2 decides how close the subject is to your current project, it works hierarchically, so in this example it would consider that entries with my subject codes 43 (Urban planning) and 4 (Building) are closely related. You can use letters instead of numbers if this suits your work.
7. Build lexicon:
This is a function which you can find in the “Lexicon” menu, and which is sometimes useful in preparation for a job which is heavy on terminology. I use this function for between 5% and 10% of my jobs. My procedure is as follows. First I call up “Build lexicon” and define the maximum number of words (usually 4). The program then takes a couple of minutes to find solutions. Then I open the lexicon (with the Project Explorer), click on the heading over the left hand column and define the sort criteria: 1. Number of words (descending), 2. Frequency (descending). Then I go through the list manually from the top. First I decide which four-word phrases are worth adding a lexicon entry for. This is usually only worthwhile for phrases which are meaningful in themselves and which occur frequently. When I get down to phrases which appear three times or less, I then use the scroll bar to move down to the most frequent three-word phrases. And so on, until I have defined a number of lexicon entries. Then I select “Remove entries” from the Lexicon menu, click on “Entries with empty targets” and OK. Typically, this gives me between 30 and 50 lexicon entries for a job consisting of several hundred segments, but they are entries which occur frequently and require consistency, so this preliminary process improves the results achieved by Pretranslate or Assemble as I work on the job.
This function (Build lexicon) can also be used to identify terms that can be used for a terminology list to be delivered to the client if this is part of the client’s instructions for the job. Over the years I have only had one such project, but this may be relevant for translators who often work in highly technical fields.
8. Names, places and proprietary titles:
These are the classic elements which should be added to the lexicon. If you have a product name or number, this is normally only relevant to the job in hand. You do not usually want this term to occur in jobs for other clients. The same applies to the names of the people who work for the client. Therefore, such elements should only be sent to the lexicon, and not to the termbase. But some names occur so often that they may be useful in the TB. My general principle here: if names could be confused with actual words in the language, they are not suitable for the TB. So the common German name Helmut is not in my TB because, depending on the level of fuzzy matching, it could be confused with the word Helm=helmet (and the declined forms Helme/Helmen/Helmes). Similarly, the surname Kohl is not in the TB to avoid confusion with Kohl=cabbage (and the near-match Kohle=coal). But the two names together are in the TB – i.e. the former German Chancellor Helmut Kohl. And other famous politicians are there too with the spelling in German and English, such as Gorbatschow/Gorbachev.
9. Adapting your use of the databases to your languages:
In some cases, your language pair and translation direction will influence the way you use the different databases because of issues such as word order and inflection. One example of this is the English phrase “public green spaces”. In French the words come in a different order, e.g. “espaces verts publics”, and alternative wordings are possible, e.g. “espaces verts des lieux publics”, “espace verts ouverts au public”, “espaces verts pour le public” etc. (Thanks to Dave Turner for providing these and other examples). In German the first translation that comes to mind is “öffentliche Grünflächen”, although the first word could also be declined as “öffentlichen”.
If you are translating from French to English, you will probably want to enter each and every French phrase as a lexical unit, especially if it occurs frequently in the type of text you deal with. Merely entering the elements does not help very much, because the order of the words must be changed. Depending on your type of work and the frequency of such phrases, you may decide to store them in the lexicon, the TB or the TM.
If you are translating from German, in this case it is sufficient to add the two words to the termbase and let DVX2 handle the endings as “fuzzy matches”. Even if we consider phrases with a greater number of inflected variants such as “public building”, (“öffentliche Gebäude”, “öffentliches Gebäude”, “öffentlichen Gebäudes”, “öffentlichem Gebäude”), it is still possible to enter just one version of each word and use fuzzy matching. The advantage here is that although the German source is inflected, the English target phrase is not.
Translating from a largely uninflected language into inflected languages like French and German can be more complicated, so you will have to find a strategy which fits the languages that you work with. There is no single solution which will work for all languages and all subject areas, but DVX2 offers flexibility in the use of the databases.
10. Looking things up in the database:
There are various ways to access the information that is in your databases. The first is that DVX2 uses this information to compile its suggested translation (when you use the functions “Pretranslate”, “Assemble” or “AutoAssemble”). When you have done that, you will see that some words or phrases in the suggested translation are underlined in blue. These are terms for which your databases contain several possibilities. Right clicking on the word or phrase will show you the other suggestions, and you can examine these and select them with the mouse or by using the number shown. The third way to see the relevant content of your database is by looking at the “Portions” window or windows. There are several screenshots illustrating this here. The fourth way to look up the information is to use Scan (CTRL-S) to call up a concordance from the TM, or Lookup (CTRL-L) to see entries from the TB.
11. Moving databases to another computer:
If you need to move your work to a different computer, e.g. to work on a laptop while you are travelling, you will need to copy certain files to the other computer. The first file is your project file, which has the extension .dvprj. The project file contains the lexicon, so no special steps are needed to transfer the lexicon. The termbase is a single file with the extension .dvtdb. The TM consists of at least four files. The main content is in a file with the extension .dvmdb. Then there is an index file for each of your languages; my index files have the extension en.dvmdi and de.dvmdi (for English and German). There is also a file with the extension .dvmdx. When you open the project on the other computer, DVX2 may complain that it cannot find the databases. But this is not a problem – when the project is open, you can select them with Project>Properties>Databases.
Another file which is worth moving to the other computer is the settings file with the extension .dvset. This contains your subject and client lists and various other settings. And don’t forget your dongle, or if you use an electronic licence key, make sure that the key will apply to the other computer.
12. How to find out more:
For more detailed information it is worth looking at the DVX2 User Guide for DVX2 Professional or DVX2 Workgroup. The link is at the bottom of the page, and the user guides are PDF files with over 600 pages. On the website http://www.atril.com there are also links to various videos, webinars and training courses, and also to the mailing list dejavu-l (under Support>Technical forum).
I already mentioned Steven Marzuola’s article on terminology databases. It is also worth looking at Nelson Laterman’s collection of tips and tricks for DVX1 (and even its predecessor DV3).
I am sure there are plenty of tips and questions which I have not covered, so I am looking forward to reading comments by my readers.
This is more than amazing!
ReplyDeleteWhere can I buy it? is it possible in Russia?
Hallo Yana, more information about the program and the supplier can be found at http://www.atril.com/. I believe there is a Russian distributor, too. You can watch an introductory video in Russian at http://www.proz.com/videos/free%20webinar%20week%20videos/1178.
ReplyDeleteThe next step would then be to download the free 30 day trial version to see if the program really meets your needs.
Hello Yana,
ReplyDeleteAtril is working with a Russian reseller: All Correct / Okey. If you prefer to purchase in Russia with local prices I would recommend you to contact them directly. You can find the contact details on our website http://atril.com/en/en/distribution-network
Best regards,
Mareike